作者:谢国琪,胡宇昊等
在AI算力需求持续增长的背景下,“异构计算”已成为提升计算效率的核心技术方向。其通过多类型处理单元的协同工作,实现计算资源的精准匹配。团队提出全国产“五合一”智能计算系统方案:飞腾CPU + 景嘉微GPU + 昇腾NPU +百度Paddle Lite + 国产OS (openEuler、OpenHarmony、银河麒麟等),为构建自主可控的算力体系、突破技术瓶颈提供解决方案。
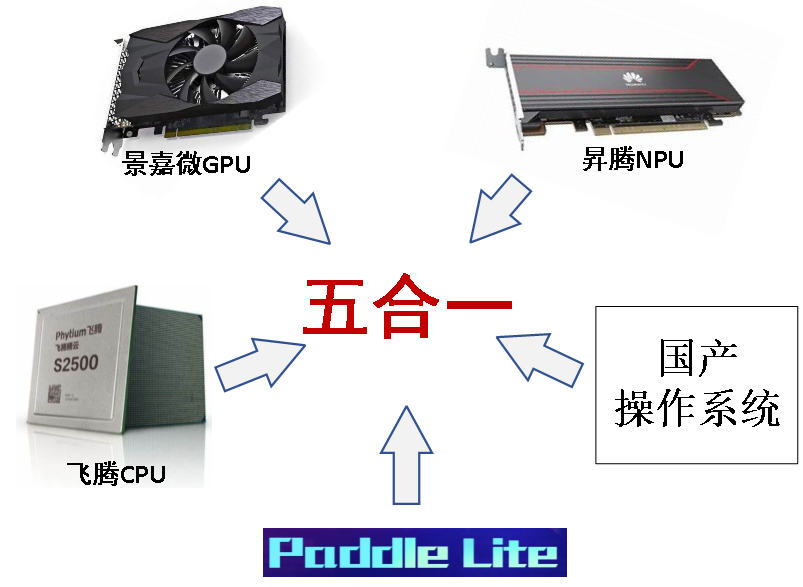
图1:国产“五合一”智能计算系统
1、什么是异构计算
异构计算的核心逻辑是“任务特性与硬件能力的精准匹配”,通过多类型处理单元的协同,最大化计算效率。在单一硬件系统中,集成CPU、GPU、NPU等多种架构不同的处理单元;系统根据任务的运算特性(如并行度、数据类型、逻辑复杂度),将其分配至最适配的处理单元,实现计算资源的高效利用。异构计算单元特点:
CPU(中央处理器):负责系统整体任务调度、串行数据处理及复杂逻辑运算,是保障系统有序运行的核心。
GPU(图形处理器):具备大规模并行计算架构,适用于数据密集型、高并行度的运算场景,如大规模数据处理、图像渲染等。
NPU(神经网络处理器):针对神经网络运算场景进行专项优化,在AI模型训练、推理等任务中,运算效率显著高于CPU与GPU。

图2:CPU、GPU、NPU
2、五合一智能计算系统方案
智能计算系统面临的框架与硬件依赖瓶颈:
1)框架依赖:AI计算长期以英伟达CUDA、谷歌TensorFlow等国外技术为核心,国内自主框架的生态覆盖范围、硬件兼容性及行业应用深度仍需提升;
2)硬件依赖:异构平台的核心加速组件(如英伟达GPU、高通NPU)多为国外产品,硬件层面的自主选择权受限,难以实现全链路国产化。
为突破上述瓶颈,“五合一”经历了从“四合一”到完整方案的技术演进。早期“四合一”构想聚焦于以“CPU+GPU+NPU+OS”搭建基础平台,但实践中发现,各硬件单元与操作系统间缺乏标准化协同机制,且缺少统一的调度框架整合异构计算资源,导致硬件能力无法形成协同效应,计算效率难以最大化。在此基础上,“五合一”方案通过新增国产AI框架,同时补充“低开销性能监控与预测”“模型异构推理”能力,形成了完整技术闭环:
基础层:由国产CPU、GPU、NPU、多类型国产OS构成,通过深度适配实现硬件与系统层面的自主可控;
核心层:引入国产AI框架,解决计算框架的“卡脖子”问题;
优化层:通过eBPF技术实现性能监控,结合模型异构推理能力,提升算力调度精度与计算效率,同时支持可视化运维与低侵入式部署。
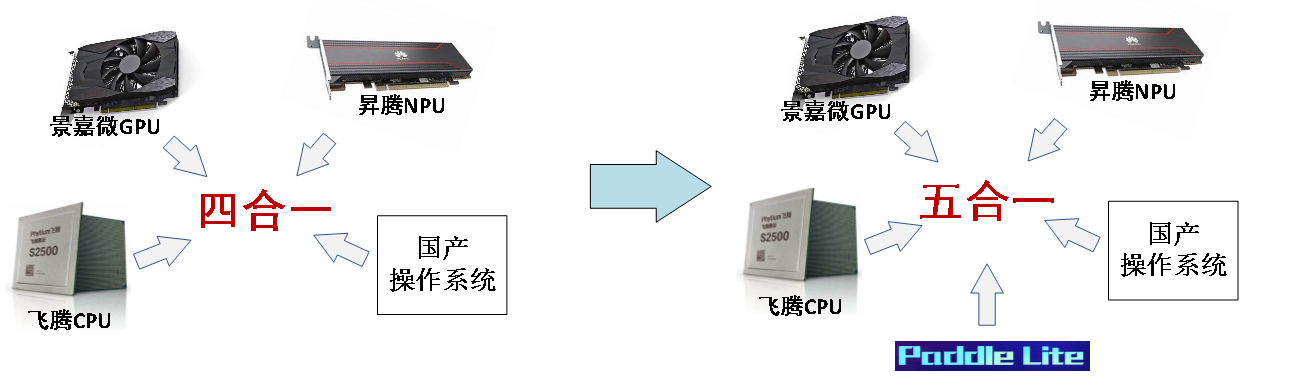
图3:“五合一”智能计算系统演进
3、“五合一”智能计算系统技术路线
第一步:搭建国产异构计算平台
选取国内技术成熟的软硬件组件,构建自主可控的异构计算基础平台,核心特性与组件包括:
硬件单元:飞腾CPU、景嘉微GPU、昇腾310PNPU,形成全栈国产化计算核心;
操作系统:深度适配各类国产OS,包括openEuler、OpenHarmony、银河麒麟等主流国产操作系统的兼容验证,可满足不同行业场景下的系统选型需求;
AI框架:搭载Paddle Lite,作为模型推理与任务切分的核心支撑;
系统特性:集成可视化管理模块,支持对异构资源状态、任务调度流程的图形化展示与操作,降低运维门槛;同时采用低侵入式设计,通过用户态技术实现核心功能,无需修改操作系统内核,大幅提升部署便捷性与系统稳定性。
第二步:构建性能监控与预测体系
通过eBPF插桩与模型拟合实现系统运行状态的实时感知与风险预判,为算力调度提供数据支撑:
图4:性能监控与预测架构图
第三步:实现模型异构推理与任务分配
通过任务拆分与精准分配,最大化各硬件单元的运算效能,具体流程包括:
图5:“五合一”智能计算系统技术架构图
4、“五合一”智能计算系统实现
“五合一”智能计算系统通过全链路可视化设计与多场景性能测试,形成了从模型导入、优化调度到结果反馈的完整闭环。系统不仅实现了国产化组件的深度协同,更通过直观的可视化界面与量化的性能数据,验证了其在实际场景中的可用性与高效性。
(1)可视化系统演示
为降低运维与调试门槛,系统构建了多维度可视化模块,实现对异构计算全流程的实时监控与操作支持:
图6:性能控与预测可视化演示
图7:模型异构推理可视化演示
(2)支持模型与性能验证结果
“五合一”智能计算系统针对主流视觉与深度学习模型开展了异构推理性能测试,通过对比不同硬件组合的推理时间(部分结果),验证了系统在任务调度、异常适配及负载均衡层面的核心能力。“五合一”智能计算系统支持Paddle Lite支持的所有模型,以下为ResNet50、SSDMobileNet等模型的具体测试结果与分析:
①ResNet50模型(图像分类)
硬件
|
平均(ms) |
最大(ms) |
最小(ms) |
| CPU |
480 |
497 |
470
|
| GPU |
1765
|
1768 |
1760
|
| CPU+GPU |
440
|
452
|
435
|
CPU+GPU与单CPU推理相比,推理速度提升1.1倍
②SSDMobileNet模型(目标检测)
硬件
|
平均(ms) |
最大(ms) |
最小(ms) |
| CPU |
167 |
169 |
164
|
| GPU |
不支持(算子维度过大)
|
| CPU + GPU |
67
|
68 |
66
|
单一GPU无法运行该模型,因部分算子输入输出Tensor维度超过GPU上限;经系统“异常算子自动替换”功能处理后,将超维度算子调度至CPU执行,CPU+GPU组合可正常推理,平均推理速度较单CPU提升2.5倍,验证了系统的兼容性适配能力;
③MobileNetV1模型
MobileNetV1测试重点验证NPU高负载场景下的异构调度优化效果,结果如下:
硬件
|
平均(ms) |
最大(ms) |
最小(ms) |
| NPU |
20
|
30 |
15
|
| CPU + NPU |
11
|
15 |
9
|
由于昇腾NPU的算力相比其余异构硬件过强(昇腾NPU 140T FLOPS)。为验证算子异构调度功能的有效性,我们选择通过提高NPU的负载,验证NPU负载提高后的调优效果:NPU高负载情况下CPU+NPU与单NPU推理相比,平均推理速度提升1.8倍
(3)核心能力验证与闭环体现
算子融合效果:针对ResNet50、YOLOv5等模型,系统自动识别可融合算子(如卷积+批归一化、激活函数串联),融合后算子数量平均减少32%,数据传输开销降低40%,直接推动推理延迟下降15%-20%。
异常适配能力:对含超维度算子的自定义图像分割模型(部分卷积算子输入Tensor维度超过GPU上限),系统通过自动识别并将异常算子调度至CPU执行,实现GPU+CPU协同推理,较单一硬件(无法运行)实现从“不可用”到“可用”。
闭环完整性:从模型导入(Paddle模型格式)、自动优化(算子融合、子图切分)、资源调度(基于eBPF监控数据动态分配),到结果输出与性能反馈(可视化仪表盘实时更新),形成端到端闭环,无需人工干预即可完成高效推理。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
