前言
JM9230是景嘉微开发的32位单精度浮点、最大算力1.2T FLOPS的国产GPU;Paddle Lite是百度开发的一款高性能、轻量级的深度学习推理引擎,专为移动端、嵌入式设备设计。将Paddle Lite与JM9230 GPU融合适配,可为AI模型的算子调度在国产平台的应用提供更多机会。嵌入式实验室的小伙伴们(胡宇昊、王渊、谢国琪老师)完成了Paddle Lite推理引擎对景嘉微JM9230 GPU的适配支持,实现了AI模型推理计算,并成功验证通过。
一、简介
景嘉微JM9230显卡
采用自主设计的国产 JM9230 高性能图形处理器。支持4路独立显示输出,支持多屏同时输出,支持4路视频解码,1路视频编码,支持OpenGL4.0、Vulkan1.1等图形编程接口,支持OpenCL3.0计算编程接口,支持4路4K@60fps HDMI2.0外视频输入。全面支持国产CPU、国产操作系统和国产固件,可广泛应用于PC、服务器、图形工作站等计算机设备,满足地理信息系统、三维测绘、三维制图、媒体处理、辅助设计、显示渲染等高性能显示需求和人工智能计算需求。

百度Paddle Lite AI框架
Paddle Lite 是百度开发的一款高性能、轻量级的深度学习推理引擎,专为移动端、嵌入式设备和物联网设备设计。它支持多种硬件平台,包括ARM、x86、MIPS、RISC-V等,并能够在Android、iOS、Linux等操作系统上运行。Paddle Lite 提供了丰富的模型优化和加速技术,如量化、裁剪和子图分割,旨在提高AI模型的推理速度和效率,同时降低计算资源的消耗。作为百度飞桨(PaddlePaddle)开源深度学习平台的一部分,Paddle Lite 能够与飞桨无缝对接,为开发者提供端到端的AI解决方案。

二、环境安装
本机环境:飞腾S2500 CPU、银河麒麟V10 SP3操作系统
2.1 景嘉微JM9230内核驱动与应用库安装
注:需先安装rpm包,再将显卡插入PCIE槽
安装包准备:
内核驱动rpm包 mwv207-dkms-1.5.0-release.ky10.aarch64.rpm
应用库rpm包 mwv207-dev-1.5.0-release.ky10.aarch64.rpm
安装命令:
$ rpm -ivh mwv207-dkms-1.5.0-release.ky10.aarch64.rpm
$ rpm -ivh mwv207-dev-1.5.0-release.ky10.aarch64.rpm
2.2 Paddle Lite编译安装
Paddle Lite版本:v2.12
参考教程:
https://www.paddlepaddle.org.cn/lite/v2.12/demo_guides/opencl.html
下载Paddle Lite源码:
$ git clone https://github.com/PaddlePaddle/Paddle-Lite.git -b v2.12
删除源码目录中的第三方库目录:
$ rm -rf third-party
编译并生成arm64的部署库:
$ ./lite/tools/build_linux.sh --arch=armv8 --with_extra=ON --with_cv=ON --with_exception=ON --with_opencl=ON full_publish
编译注意事项:
Paddle Lite默认使用4核编译,建议先使用
$ export LITE_BUILD_THREADS=$(CPU_NUMs)
提高编译使用CPU核数后,再进行编译
三、模型推理&结果演示
3.1 Paddle Lite Demo下载
在Paddle-Lite源码目录中执行命令:$ wget https://paddlelite-demo.bj.bcebos.com/devices/generic/PaddleLite-generic-demo_v2_12_0.tar.gz
解压:
$ tar -xvf PaddleLite-generic-demo_v2_12_0.tar.gz
3.2 替换编译好的Paddle Lite库
执行命令:
# 替换 include 目录
$ cp -rf build.lite.android.armv8.gcc/inference_lite_lib.android.armv8.opencl/cxx/include/ PaddleLite-generic-demo/libs/PaddleLite/android/arm64-v8a/include/
# 替换 libpaddle_light_api_shared.so
$ cp -rf build.lite.android.armv8.gcc/inference_lite_lib.android.armv8.opencl/cxx/lib/libpaddle_light_api_shared.so PaddleLite-generic-demo/libs/PaddleLite/android/arm64-v8a/lib/opencl/
# 替换 libpaddle_full_api_shared.so
$ cp -rf build.lite.android.armv8.gcc/inference_lite_lib.android.armv8.opencl/cxx/lib/libpaddle_full_api_shared.so PaddleLite-generic-demo/libs/PaddleLite/android/arm64-v8a/lib/opencl/
3.3 推理模型
进入模型demo目录
在Paddle-Lite源码目录下执行:
$ cd PaddleLite-generic-demo/image_classification_demo/shell/
重新编译demo:
$ ./build.sh linux arm64
使用景嘉微JM9230 GPU进行Resnet50模型推理:
$ ./run.sh resnet50_fp32_224 imagenet_224.txt test linux arm64 opencl
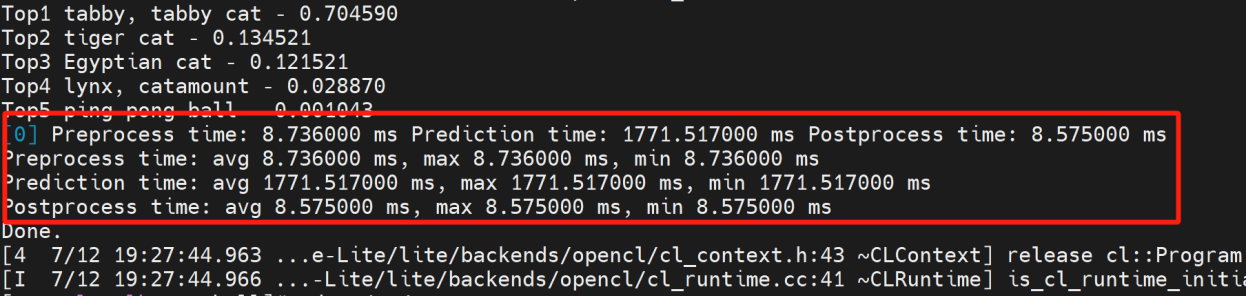
推理结果演示:
3.4 注意事项
Paddle Lite使用openCL+GPU进行模型推理时,要注意动态库的查找路径,服务器版的Linux系统动态库的路径为/usr/lib64,因此景嘉微GPU的应用库安装路径为/usr/lib64/mwv207。而Paddle Lite对与动态库的搜寻路径桌面版的系统路径/usr/lib/aarch64-linux-gnu 优先级大于服务器版。建议将/usr/lib/aarch64-linux-gnu 路径中的openCL库软链接到正确路径:
$ ln -s /usr/lib64/mwv207/libOpenCL.so.3.0.0 /usr/lib/aarch64-linux-gnu/libOpenCL.so
总结
湖南大学嵌入式实验室在飞腾S2500 CPU+银河麒麟V10操作系统上,成功实现百度Paddle Lite + 景嘉微JM9230 GPU的适配。通过异构计算资源的有机组合,发挥各类硬件的计算优势,实现高效和灵活的 AI 模型算子调度,该创新实践为 AI 应用在全国产异构计算平台的运行提供了适用的技术方案,展示了其在性能优化和异构计算资源利用方面的效果。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
